
Adaptive Draft-Verification for Efficient Large Language Model Decoding
Published:
We introduce an LLM decoding acceleration method that requires no fine-tuning. Our approach involves an adaptive draft-verification process that evolves over time to improve efficiency. We utilize a tri-gram matrixbased LLM representation to dynamically approximate the output distribution of the LLM, allowing the model to adjust to changing token probabilities during the decoding process. 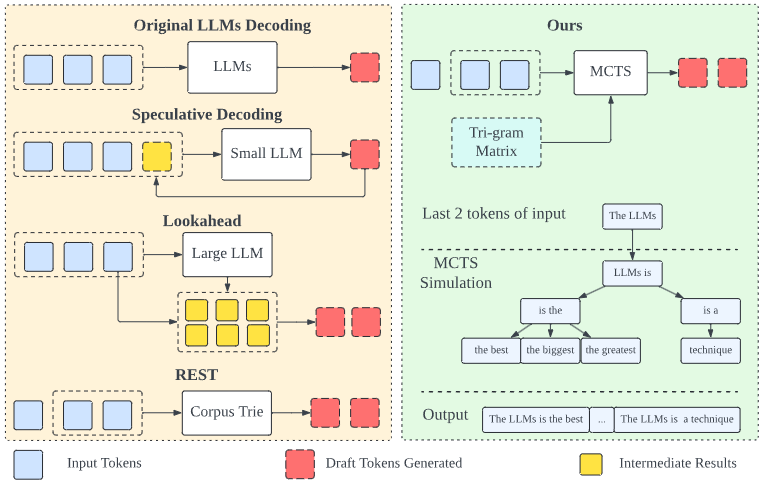
Leave a Comment